
The KNIME Row Splitter Node is the exact same node as the Knime Row Filter node, which we previously blogged about. In the product it’s the first sentence they use to explain the row splitter node. It’s not entirely true because it also passes the false in the boolean equation.
I expect you will read the KNIME Row Filter node blog to learn how to use the Row Splitter node and below I will explain the only difference between the two, in this blog on the KNIME Row Splitter node. Good luck!
If you’re familiar with Alteryx’s Filter tool, you’re familiar with the KNIME row splitter node! (which is explained entirely in the row filter node blog that I’m going to suggest over and over because it explains how to use this tool!)
What’s the difference between Row Splitter Node and the Row Filter Node? It allows both true and false data to stream through your filtering at a row level…
In knime, the KNIME row splitter node is my go to filter because it’s what the where clause wish it could do too. Think about the where clause, you are removing data, row splitter lets you keep both true and false of any of those conditions you can manually come up with or automatically generate in your pipeline.
When writing SQL, the where clause is WHERE you filter out data, the Row splitter in knime is also a filter/splitter, and it allows you to split the things that match or do not match. This generates two different streams that can be used as many times as you desire.
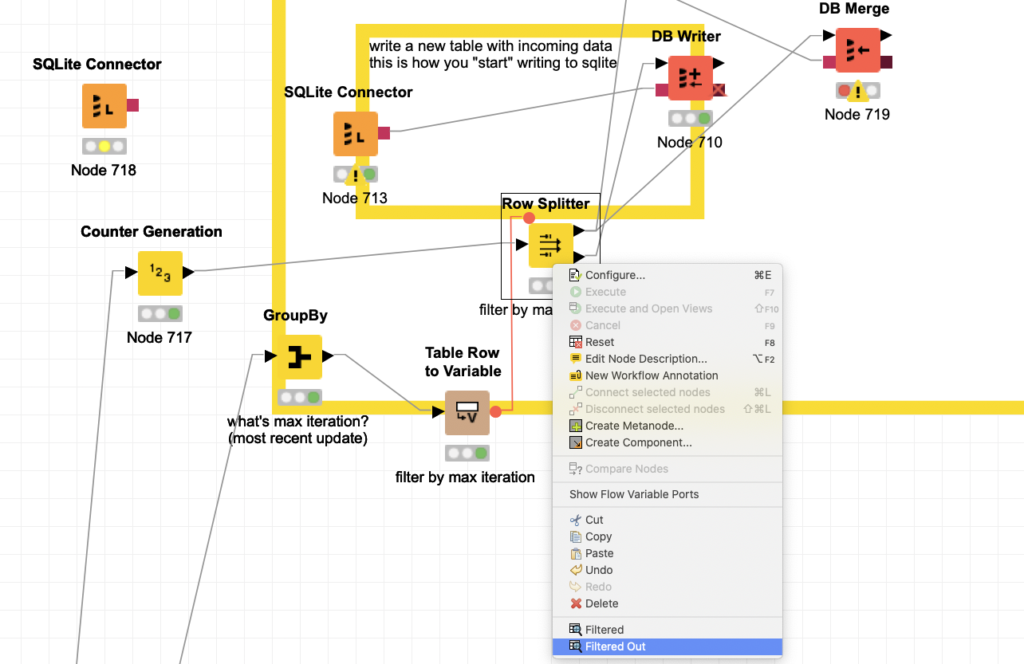
Clicking Filtered or Filtered Out will show you two different sets of data. The boolean condition, true or false, will be falling into these buckets and this right click screenshot above is how you can view this data. This is the only difference from the row filter node.
Whenever I’m using this node I like to think “at a row level, this is equal to the following…” and the ability to get the false side of this equation is rather handy. Remember this is another set of data, if it’s large, might as well use the row filter node VS using the row splitter node.
KNIME Row Splitter Node is re-usable and here you can see these different streams of data offer you the ability to “try again.” I like this ability and I also enjoy how row splitter node lets me keep what I filtered to double check if I’ve made any mistakes in my filtering.
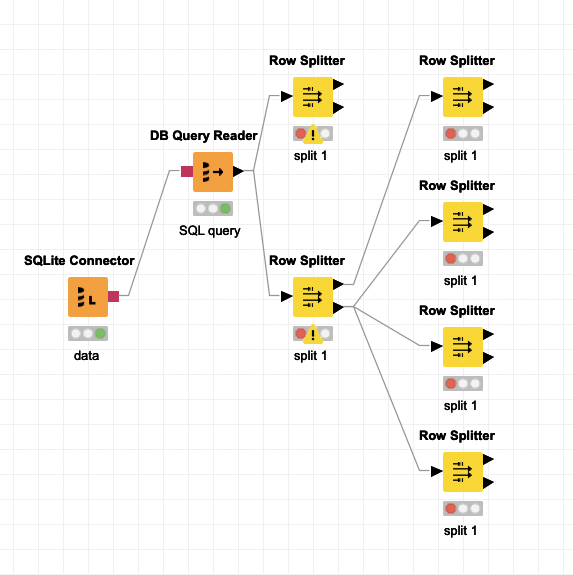
Above screenshot we are illustrating you can re-use all the streams, true or false. This is the cool aspect of row splitter. Also it’s a cool aspect of KNIME, allowing you to quickly re try something over and over from the same stream of data in your data pipeline.
If you’re looking for a massive PNG of the KNIME Row Splitter, here you go mate. #yolo

A grade A Screenshot of Knime Row Splitter. Knime exports SVGs, I converted this one into a PNG.
Here’s what KNIME has to say about the KNIME Row Splitter node. Personally, I have a lot of trouble reading big paragraphs of text and prefer breaking things into bullets before I’m able to completely comprehend the information. Hope it helps below. My edits are simply breaking this into bullets, however this information can be found inside of the product under View/Descriptions.
KNIME explains Row Splitter Node
- This node has exactly the same functionality as the Row Filter node.
- Except for that it has an additional output that provides the rows that are filtered out.
- For performance and disk space reasons you may want to consider using the Row Filter node.
- The table at the upper port (with index 0) contains the rows included in the result according to the filter criteria (the node settings).
- The lower port (with index 1) provides a table with all rows not matching the filter criteria.
- The sum of the number of rows in the two output tables is the same than the number of rows in the input table.
Following is a copy of the node description of the Row Filter node:
- The node allows for row filtering according to certain criteria.
- It can include or exclude: certain ranges (by row number), rows with a certain row ID, and rows with a certain value in a selectable column (attribute).
- Below are the steps on how to configure the node in its configuration dialog.
- Note: The node doesn’t change the domain of the data table. I. e. the upper and lower bounds or the possible values in the table spec are not adapted, even if one of the bounds or one value is fully filtered out.
KNIME – Row Filter – Dialog Options
In- or exclude rows by criteria
- You must first select which criteria should be used for filtering from the left-hand side.
- Also choose whether to include or exclude rows according to the selected criteria.
- Depending on the choice, you will then have to adjust the filter parameters in the right-hand panel.
Column value matching
- If filter by attribute value is selected, select the name of the column whose value should be matched.If the selected column is a collection column the filter based on collection elements option allows to filter each row based on the elements of the collection instead of its string representation.
- Then, either enter a pattern for string matching, or a value range, for range filtering.
- When using a pattern match, you can set checkmarks according to whether the pattern contains wildcards or is a regular expression.
- Wildcard patterns contain ‘*’ (matching any sequence of characters) and ‘?’ (matching any one character).
- Examples of regular expressions are given below. Also, a case sensitive match can be enabled by the according checkmark.
- Note: if you select a pattern from the drop-down menu of the pattern text field, the node still performs a comparison of the string representation of the data values.
- If a range is specified, and you specify only one boundary, the other is then set to (plus or minus) infinity.
- Here are some examples of regular expressions:
- “^foo.*” matches anything that starts with “foo”.
- The ‘^’-character stands for the beginning of the word, the dot matches any (one) character, and the asterisk allows any number (including zero) of the previous character.
- “[0-9]*” matches any string of digits (including the empty string).
- The [ ] define a set of characters (they could be added individually like [0123456789], or by range). This set matches any (one) character included in the set.
For a complete explanation of regular expressions see e.g. the JavaDoc of the java.util.regex.Pattern class.
Row number range
If filter by range is selected, specify the first row number to in/exclude. The end of the range can either be specified by row number, or set to the end of the table, causing all remaining rows to be in/excluded.
Row ID pattern
If filter by row ID is selected, specify a regular expression, which is matched against the row ID of each row. A checkmark can be set, if a case sensitive match should be performed and if the row ID should start with the specified pattern.
Ports
Input Ports
| 0 | Datatable from which to filter rows. |
Output Ports
| 0 | Datatable with rows meeting the specified criteria |
| 1 | Datatable with rows not meeting the specified criteria |
Trackbacks/Pingbacks