
KNIME File Reader Node helps people automate opening different file types. In this lesson, we will discuss how we can use the File Reader Node to read an incoming file.
Reading files with the File Reader Node is my personal preference when working with flat files, like a CSV file.
The File Reader Node does a bit of automation and helps you read files in an automated fashion!
To begin, you will need a new sample set of data.
Start by downloading the “Canada_Analytics-City-State-LinkedIn-3-9-19.csv” flat file from google drive. I built the source of data using KNIME Analytics Platform and scraped LinkedIn’s Job Data.
Once you’ve downloaded this CSV file with Canada analytics job type data, you can begin reading the file.
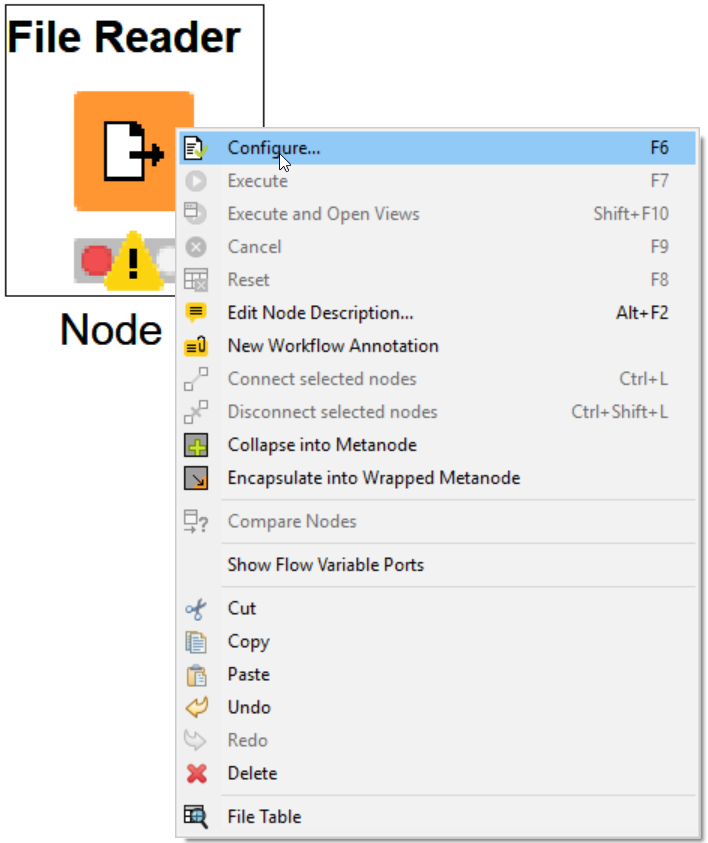
Using File Reader Node
The File Reader Node is relatively straight forward. The file reader node is a lot like the Alteryx input too, set to “files.”
Once you open your configure dialog window, browser for the Canada CSV. Open the file in your config window.
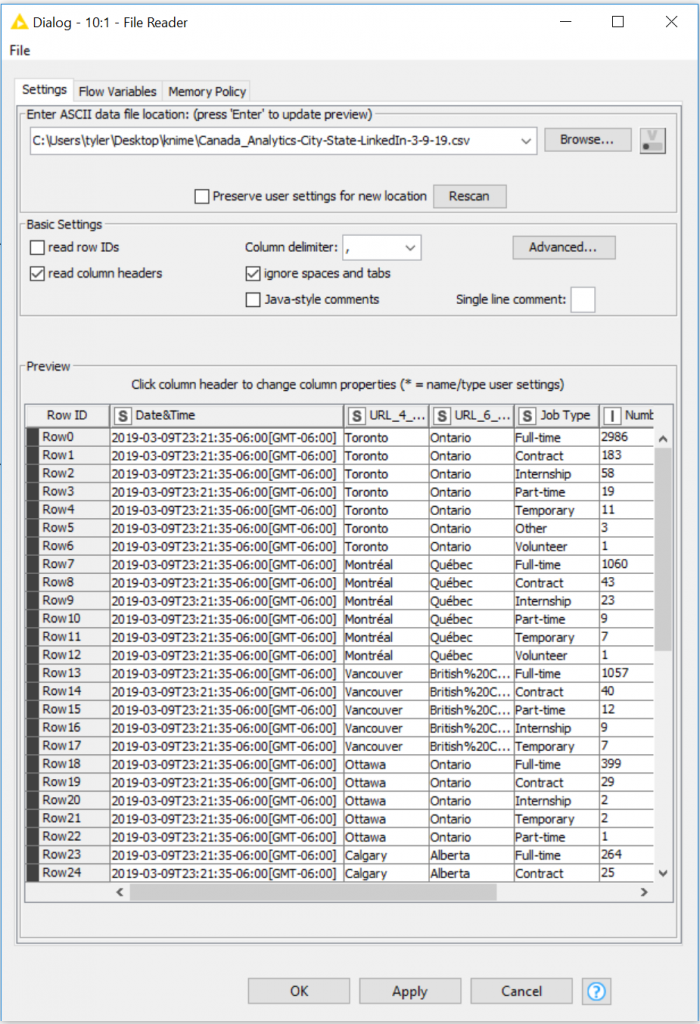
The File Reader Node offers a quick demo of the data passing through.
Leaving everything default, your new CSV file will now render appropriately on your screen.
Click okay, let’s execute our node to ensure the File Reader Node is working correctly, and right click to open your cached data. My macro button to open these windows is B.

Perfect, you read your first CSV file.
File Reader has a good opportunity to play with header-less files too.
To learn more – download the next sample set, which is similar to the Canada data BUT we don’t have headers and it’s USA data.
Once downloaded, browse to the file and open the data to preview in the configuration dialog.
If you have “read column headers” checked – notice the column headers in the preview has consumed your first row of data.
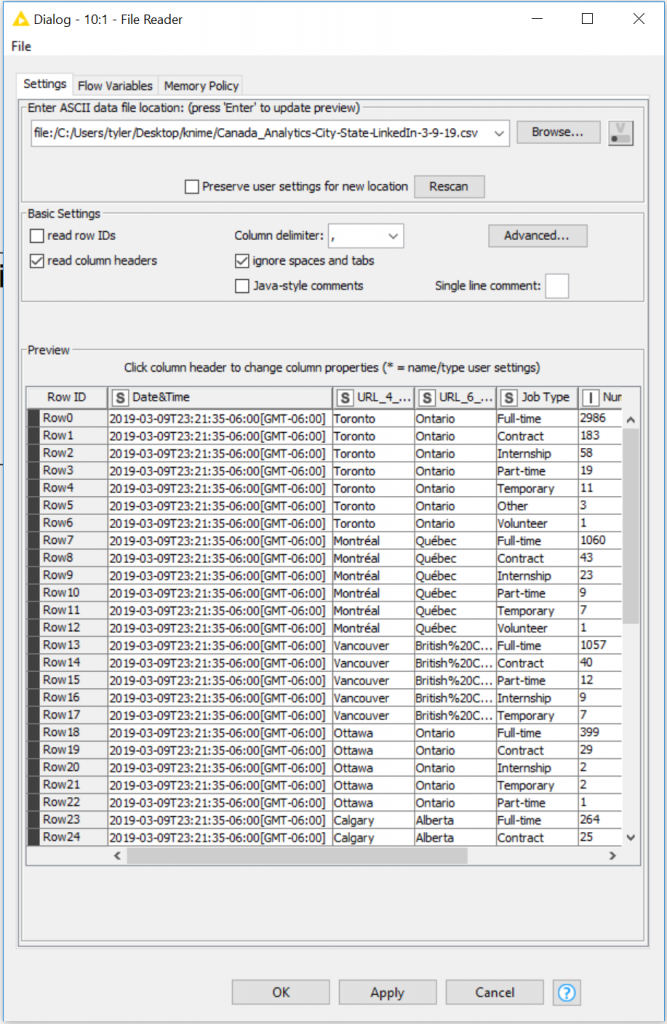
Un-check read column headers…
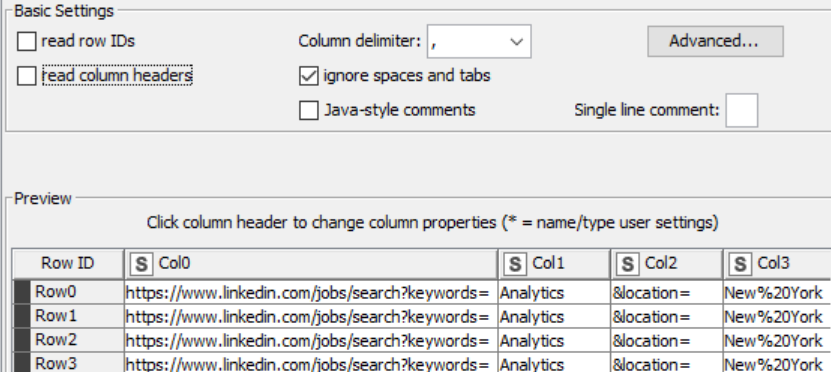
We now have headers that are numbered and prefixed with Col, which stands for Column. These particular naming conventions are not going to help our end users, changing column headers will be our next step.
You can EDIT by single clicking on any column header in this screen… However, if you change the file path, you will lose your header renames, and you will not be alerted of these changes or loss of work.
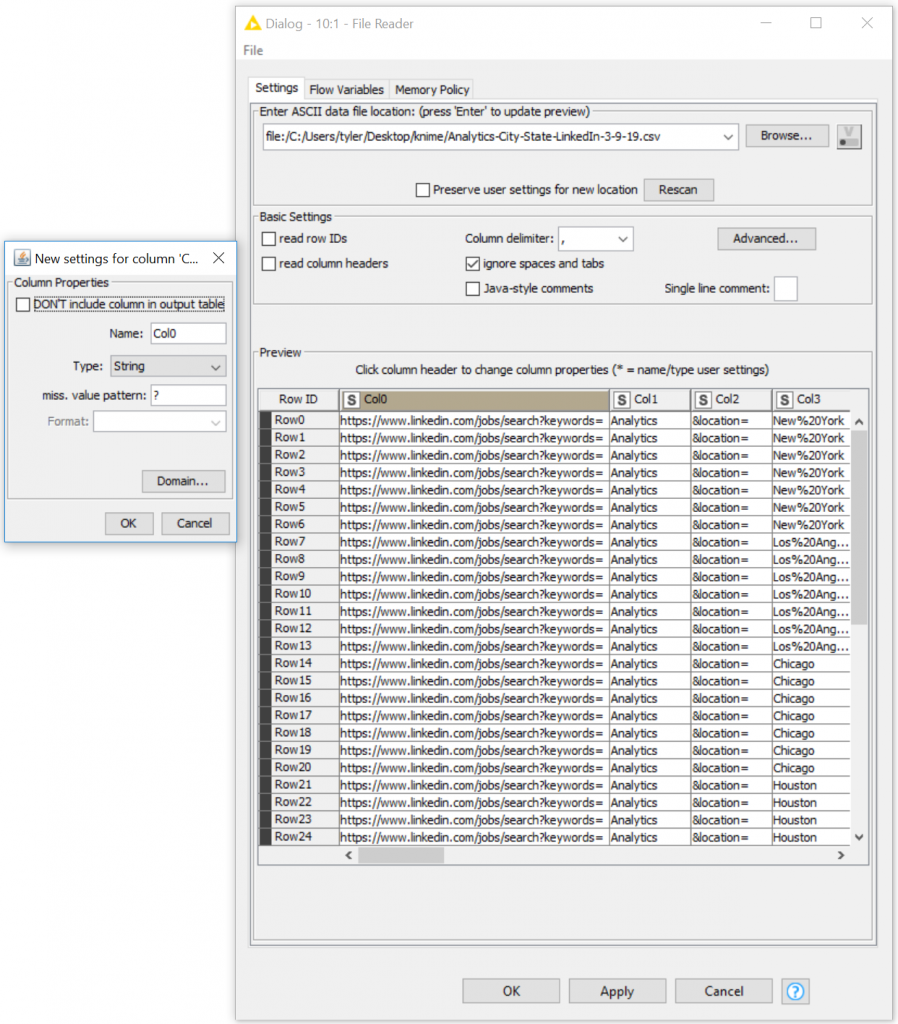
I do not recommend spending a lot of time renaming columns in the KNIME File Reader Node because it only happens here, in this one input.
It’s better to rename later upstream and remove the potential of losing everything because you made 1 edit. You can keep these headers if you
Preserve user settings but again, it only solves your one input. To solve more inputs, it would require you to keep track of the
Preserve user settings and also be willing to copy and paste the file reader, so that your user settings would scale as you change the file destination.
Getting super stressed or tied into a flat file automation world should not be your desire or end goal. Databases are free and easier to scale your work as you advanced in the analytics field. However, flat files are in our lives, so lets automate it.
Advanced File Reader Node Settings
Advanced settings will make you feel right at home if you’re familiar with supporting file reading solutions, and if it’s your first time – please do not be afraid to read and fail.
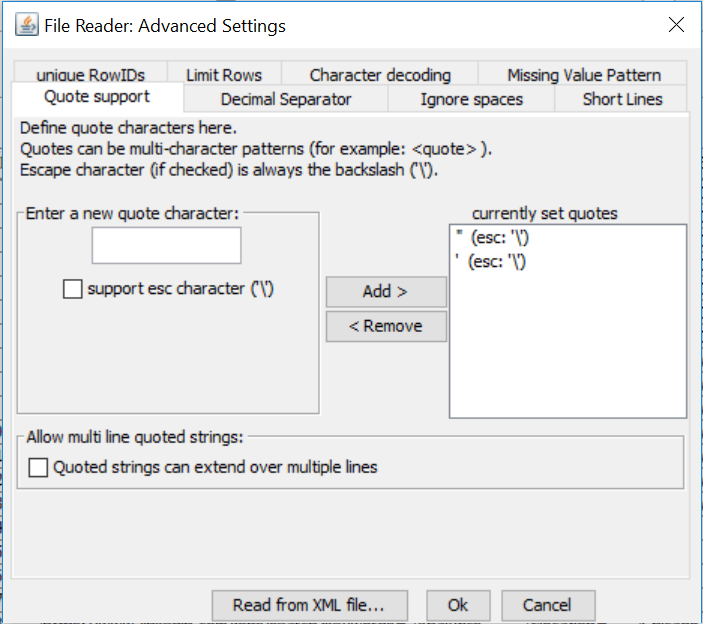
You can limit your rows, change null values, ignore space, edit your types of quotes and also a decimal separator solution. These become relative as you need them, depending on your use case. You don’t need to master these individual windows to become an analytics app developer!
Node description for File Reader
KNIME > Node Descriptions > IO > Read
This node can be used to read data from an ASCII file or URL location. It can be configured to read various formats.
When you open the node’s configuration dialog and provide a filename, it tries to guess the reader’s settings by analyzing the content of the file. Check the results of these settings in the preview table. If the data shown is not correct or an error is reported, you can adjust the settings manually (see below).
The file analysis runs in the background and can be cut short by clicking the
“Quick scan”, which shows if the analysis takes longer. In this case the file is
not analyzed completely, but only the first fifty lines are taken into account.
It could happen then, that the preview appears looking fine, but the execution
of the File Reader fails, when it reads the lines it didn’t analyze. Thus it is
recommended you check the settings, when you cut an analysis short.
KNIME – File Reader – Dialog Options
- This node can be used to read data from an ASCII file or URL location. It can be configured to read various formats.
- When you open the node’s configuration dialog and provide a filename, it tries to guess the reader’s settings by analyzing the content of the file.
- Check the results of these settings in the preview table.
- If the data shown is not correct or an error is reported, you can adjust the settings manually (see below).
- The file analysis runs in the background and can be cut short by clicking the “Quick scan”, which shows if the analysis takes longer.
- In this case the file is not analyzed completely, but only the first fifty lines are taken into account.
- It could happen then, that the preview appears looking fine, but the execution of the File Reader fails, when it reads the lines it didn’t analyze.
- Thus it is recommended you check the settings, when you cut an analysis short.
Enter a valid file name or URL
- When you press ENTER, the file is analyzed and the settings pre-set.
- You can also choose a previously read file from the drop-down list, or select a file from the “Browse…” dialog.
Preserve user settings
- If checked, the checkmarks and column names/types you explicitly entered are preserved even if you select a new file.
- By default, the analyzer starts with fresh default settings for each new file location.
Rescan
- If clicked, the file content is analyzed again.
- All settings are reset (unless the “Preserve user settings” option is selected) and the file is read in again to pre-set new settings and the table structure.
Read row IDs
- If checked, the first column in the file is used as row IDs.
- If not checked, default row headers are created.
Read column headers
- If checked, the items in the first line of the file are used as column names.
- Otherwise default column names are created.
Column delimiter
Enter the character(s) that separate the data tokens in the file, or select a delimiter from the list.
Ignore spaces and tabs
If checked, spaces and the TAB characters are ignored (not in quoted strings though).
Java style comment
- Everything between ‘/*’ and ‘*/’ is ignored.
- Also everything after ‘//’ until the end of the line.
Single line comment
- Enter one or more characters that will indicate the start of a comment (ended by a new line).
Advanced…
- Opens a new dialog with advanced settings. There is support for quotes, different decimal separators in floating point numbers, and character encoding.
- Also, for ignoring whitespaces, for allowing rows with too few data items, for making row IDs unique (not recommended for huge files), for a global missing value pattern, and for limiting the number of rows read in.
Click on the table header
- If the column header in the preview table is clicked, a new dialog opens where column properties can be set: name and type can be changed (and will be fixed then).
- A pattern can be entered that will cause a “missing cell” to be created when it’s read for this column.
- Additionally, possible values of the column domain can be updated by selecting “Domain”.
- And, you can choose to skip this column entirely, i.e. it will not be included in the output table then.
Ports
Output Ports
| 0 | Datatable just read from the file |
This node is contained in KNIME Core provided by KNIME AG, Zurich, Switzerland.